
SQLD 通过心得及资料
SQLD 通过心得
 이미지를 불러올 수 없습니다.
이미지를 불러올 수 없습니다.
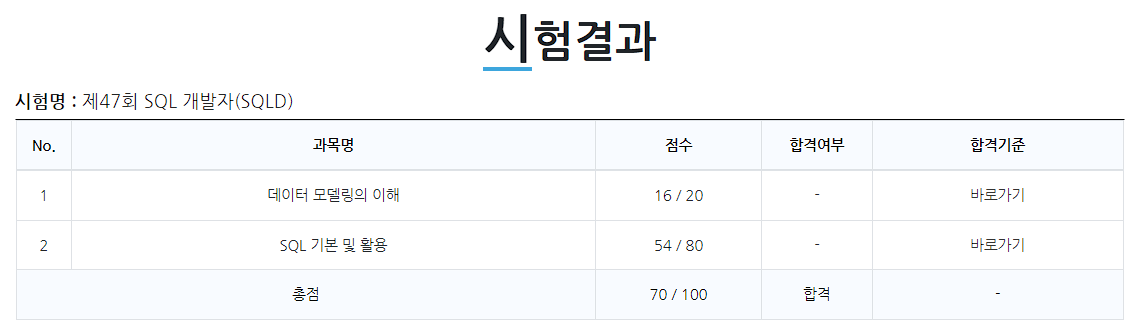
我通过了第47届SQL开发者资格考试。这是我在彻底改变职业方向后考取的第一张证书,因此感到非常自豪。
起初我本想投入一个月左右的时间,但后来被其他事情耽搁,或者过于理论化地去学习……感觉浪费了不少时间,这让我有些遗憾。在此记录下学习过程中总结的一些要点。
最后一部分记录了个人整理的概念,其中包含一些实操内容,以及为了便于记忆而进行的编辑,因此可能存在某些地方与实际情况不符!不过,考虑到或许能对他人备考有所帮助,我决定保留全部内容,日后若想起会再进行修改。
耗时及学习方法
实际花费的时间约为2周,其中解题大约耗时1周。
起初,我本想通过[Data on Air](https://dataonair.or.kr/
)提供的概念讲解,以一种近乎“王道”的方式进行学习,但发现SQLD考试本身提供的题目中,以实战SQL语句形式呈现的题目远多于概念性内容,因此我在初期就放弃了这种方式。不过,我仍然认为其内容本身很不错,如果时间充裕,建议大家去看看!
接下来,我通过YouTube上各种形式的讲座掌握了大致的框架。仅就SQLD而言,已有相当数量的系统化讲座,因此挑选看起来不错的课程即可。
最后是解题环节。关于习题,相关论坛或博客上都有复原历年真题的资料。俗称 “黄皮书”虽然不错,但切勿忽视对真题的解题练习!我仅对黄皮书的前两章进行了通读并整理了错题笔记,剩余时间全部用于真题练习。
个人推荐的真题复原合集网站是[这个博客](https://yunamom.tistory.com/category/자격증/SQLD 기출문제
)。因为只需输入答案,就能立即确认该题的正误。
概念整理
参考事项:由于第1章的习题比重小于第2章,因此被排在后序,相应地仅记录了必要内容,内容可能不够充分
第1单元
实体的分类
-
基本/主键实体
-
核心实体
-
行为实体
数据建模
-
用于构建信息系统的数据视角业务分析技术
-
通过约定好的表示法来表达现实世界中的数据
-
用于构建数据库的分析/设计过程
进行数据建模时的注意事项
-
冗余
-
缺乏灵活性
-
不一致
数据建模的类型
-
概念型:抽象层次较高,以业务为中心进行全面建模
-
逻辑型:准确表达键、属性、关系等,设计时注重可重用性
-
物理型:考虑物理特性,以便移植到实际数据库中。
数据库模式的结构
-
外部
-
概念
-
内部
ERD绘制顺序
- 绘制实体。
- 合理布局实体。
- 设定实体之间的关系。
- 标注关系名称。
- 标注关系参与度。
- 标注关系的必选性。
实体的特征
-
该业务中需要且必须管理的信息
-
必须是唯一的标识符。
-
拥有两个或以上的实例。
-
必须实际被使用。
-
必须拥有属性。
-
必须形成至少一个关系。
1개 엔터티: 2개 이상의 인스턴스 집합 + 2개 이상의 속성
1개 속성: 1개 이상의 속성값
根据属性特征的分类
-
基本属性
-
设计属性
-
派生属性
域
-
各属性可能取值的范围
-
指定实体内属性的数据类型、大小及约束条件
属性命名
-
必须是该业务中使用的名称。
-
不使用描述性属性名。
-
尽量避免使用缩写。
-
必须确保在整个数据模型中具有唯一性。
ERD中不区分存在关系和行为关系。 但在类图中需进行区分,并描述关联关系和依赖关系。
关系的表示法
-
关系名:关系的名称
-
关系度:1 : 1, 1 : M, M : N
-
关系选定规格:必选、可选
关系解读
-
基准实体读作“1个”(One)或“每个”(Each)。
-
解读目标实体的关系参与度。
-
解读关系选定规格和关系名称。
标识符类型
-
代表性:主标识符 vs 辅助标识符
-
自生成性:内部 vs 外部
-
单一属性标识:单一 vs 复合
-
是否具有语义:本质 vs 人为
主标识符的特征
-
唯一性
-
稀有性
-
不变性
-
存在性
性能数据建模
以提升数据库性能为目的,将性能相关事项反映到数据建模中
第一范式规范对象
-
分离冗余属性
-
行级重复
-
列级重复
反规范化
通过规范化实体、属性及关系的重复、整合与分离 提升系统性能,简化开发与运维 当预计性能下降时,即使可能导致完整性受损,仍可执行。
流程
-
调查反规范化的对象
-
范围处理频率
-
大量范围处理
-
统计性处理
-
表连接(JOIN)数量
-
-
若可通过其他方法实现,则考虑引导采用该方法
-
连接(JOIN)较多的情况,使用视图表
-
处理大量数据时,采用聚簇
-
持有大量数据时,通过分区进行数据分割
-
索引维护
-
应用程序逻辑变更
-
超级/子类型数据模型转换技术
单独发生的事务 -> 单独的表 超级 + 子类型 -> 超级 + 子表 整体 -> 单一表
确定主键顺序的标准
-
指定以高效利用索引
-
位于前面的属性值应作为比较条件
-
尽可能使用 '=', BETWEEN, '<>'
分布式数据库的优缺点
优点
-
区域自治性,可逐步扩展系统容量
-
可靠性与可用性 / 实用性与灵活性
-
响应速度快,降低通信成本,更好地满足区域用户需求
-
提高数据可用性与可靠性,便于调节系统规模
缺点
-
开发成本及潜在错误增加,处理成本上升,威胁数据完整性
-
设计过程困难,管理复杂且成本高,响应速度不稳定,难以控制
第2单元
SQL语句的种类
DCL
数据控制语言(Data Control Language),用于管理权限的命令
GRANT
-
授予权限的作用
-
采用
GRANT {permission} ON {table} TO {user};
的形式使用
```text
WITH GRANT, WITH ADMIN의 비교
GRANT: 특정 사용자에게 권한 부여가 가능한 권한을 부여, 부여한 부모의 권한이 회수될 때 자식의 권한도 회수
ADMIN: 테이블에 대한 모든 권한을 부여, 부여한 부모의 권한 회수와 관계 없는 권한
```
REVOKE
-
用于撤销权限
-
采用
REVOKE {permission} ON {table} FROM {user};
的形式
权限的种类
ALL -- 모든 권한 부여
SELECT INSERT UPDATE DELETE /* */
REFERENCES ALTER INDEX /* */
/* ROLE: 다양한 권한을 하나의 그룹으로 묶어서 관리 */
CREATE ROLE {role_name}; -- 권한 그룹 생성
GRANT {permission_type} TO {role_name}; -- 해당 그룹에 권한 등록
GRANT {role_name} TO {user_1}, {user_2}...; -- 다른 유저들에게 권한 그룹 부여
DDL
数据定义语言(Data Definition Language),用于定义数据的命令
以SQL Server为例,支持自动提交(Auto Commit)
CREATE
-
创建表结构
-
采用
CREATE TABLE {table_name} {table_elements};
的形式
```sql
CREATE TABLE EXAMPLE (
/*
컬럼명은 영어, 한글, 숫자 전부 가능
첫 글자를 문자로 지정해야 하며, 컬럼의 데이터 타입은 반드시 설정해야 한다.
*/
NAME varchar2(max_length) -- 최대 길이를 가진 가변길이 문자열
ID번호 char(length) -- 고정된 길이 문자열
나이_2 number(max_length) -- 숫자형 데이터 타입
생일 date -- 날짜형 데이터 타입
);
```
*
##### CONSTRAINT (条件)
* default:指定默认值
* not null:不允许输入NULL
* primary key:指定主键(not null、unique,支持多主键)
* foreign key:指定外键(支持多外键)
ALTER
-
用于修改表及列的名称、属性,以及进行结构修改(如添加、删除等)
-
采用
ALTER TABLE {table_name} {detail_order} {detail_property(if need)} TO {change_target};
的形式使用
*
#### 详细命令
* RENAME:更改表、列的名称
* MODIFY:更改列的属性
* ADD:添加列
* DROP:删除列
* ADD CONSTRAINT / DROP CONSTRAINT:添加、删除约束
*
RENAME
-
无需通过 ALTER 即可更改表或列的名称
-
可同时更改多个表名
DROP
- 无需通过 ALTER 即可删除表或列
*
#### TABLE {table_name} CASCADE CONSTRAINT
* 仅存在于 Oracle 的选项,SQL Server 中不存在
* 对于外键约束,先删除引用表,再删除该表。
* 同时删除该表数据及所有外键引用约束
TRUNCATE
-
表初始化 (并非删除!)
-
仅清除内部数据,表的存在及列结构仍保留。
*
#### DROP vs TRUNCATE vs DELETE
* DROP:彻底删除表并释放内存
* TRUNCATE:保留表和列的存在,仅释放剩余数据的内存
* DELETE:删除记录,数据操作日志保留,可在提交前回滚,且不释放内存
DML
数据操作语言(Data Manipulation Language),用于操作记录的命令
INSERT
-
将数据插入记录
-
采用
INSERT INTO {table_name} {column_name} VALUES {change_column_name};
的形式
- 虽可不指定列名进行插入,但若未指定,则必须填入所有字段值
*
UPDATE
-
修改现有数据
-
采用
UPDATE {table_name} SET {column_name} = {column_value} WHERE {condition};
的形式
DELETE
-
删除现有数据
-
采用
DELETE FROM {table_name} WHERE {condition};
的形式
- 可省略FROM
*
SELECT
-
查询特定数据
-
采用
SELECT {select_target} FROM {select_origin} WHERE {condition};
的形式
- 也可使用
GROUP BY {calc_type} HAVING {condition} / ORDER BY {sort_condition}
的形式添加条件
*
#### DISTINCT
用于查询不包含重复值的条件 (a, b, NULL, a, b, NULL) => (a, b, NULL)
COUNT
(\*): 统计包含 NULL 值的全部行数
({column\_name}): 统计特定列的行数(不包含 NULL 值)
TCL
事务控制语言(Transaction Control Language),事务控制命令
事务(Transaction):改变数据库状态的操作
* transaction의 특징
고립성: 실행되는 동안 다른 transaction에 영향을 받아 잘못된 결과를 만들면 안됨
일관성: 실행 전 데이터베이스에 잘못된 점이 없다면 transaction 수행 후에도 내용에 오류가 있으면 안됨
지속성: transaction이 갱신한 데이터베이스 내용은 영구적으로 저장
원자성: transaction에서 정의한 연산은 모두 성공적으로 실행되거나 전혀 실행되지 않음 (All or Nothing)
COMMIT
- 将数据变更反映到数据库中
SAVEPOINT
-
指定保存点(savepoint)作为代码分割的分支点
-
采用
SAVEPOINT {savepoint_name};
的形式使用
*
ROLLBACK
-
用于恢复到先前状态的命令
-
可回滚至SAVEPOINT或上一次COMMIT
-
使用形式为
ROLLBACK TO {rollback_point}; -
若无SAVEPOINT,则恢复至最近一次COMMIT
TCL的效果
-
保障数据完整性
-
在永久更改数据前确认数据变更情况
-
可对具有逻辑关联的操作进行分组处理
函数
字符型函数
常用于指定 SELECT、WHERE 等条件
LOWER
- 将英文字符串转换为小写
*
UPPER
- 将英文字符串转换为大写
CONCAT
-
合并两个字符串
-
与 Oracle 的 '||'、SQL Server 的 '+' 功能相同
SUBSTR
- 从字符串的第 M 位开始,保留 N 个字符并删除其余部分
*
LENGTH, LEN
- 包含空格的字符串长度
*
TRIM, LTRIM, RTRIM
- 移除两端指定的字符;若未指定字符,则移除空格
数值型函数
ROUND
- 四舍五入
*
TRUNC
- 向下取整
CEIL
- 取不小于该数的最小整数
FLOOR
- 取不大于该数的最大整数
MOD
- 模运算
SIGN
- 正数返回 1,0 返回 0,负数返回 -1
ABS
- 绝对值
日期型函数
SYSDATE
- 输出执行查询时的当前日期和时间
EXTRACT
- 以
EXTRACT ({information} FROM {data})
的形式使用
- 如何从日期型数据中提取所需值
类型转换
可通过这些函数更改数据类型
TO_NUMBER
字符串 > 数字
TO_CHAR
数字、日期 > 字符串(根据格式不同生成结果)
TO_DATE
字符串 > 日期(根据格式不同生成结果)
基本结构
DECODE
-
IF语句
-
当条件可以简单整理时
*
CASE WHEN
-
扩展版的 IF 语句
-
当需要对条件进行较长整理时
ORDER BY
-
对查询到的表进行排序
-
可以使用多个排序条件
*
WHERE
-
IN, NOT IN:只要列表中的值与其中任意一个匹配或不匹配,即满足条件
-
IS NULL, IS NOT NULL:判断是否为NULL,返回T/F
-
BETWEEN a AND b:检查值是否在a和b之间,返回T/F(包含a和b)
-
比较运算符:=, >, <, >=, <= 等
-
A LIKE B:根据a查找与b相似的字符串
-
%:表示存在一个或多个字符
-
_:表示一个字符
명시적 형변환 vs 암시적 형변환
명시적 형변환: 함수를 활용하여 데이터 타입을 변경
암시적 형변환: 데이터베이스가 알아서 바꿔주는 것
>> 숫자 타입의 PK는 암묵적으로 인덱스가 되는데 데이터의 조회 등으로 암시적 형변환이 발생한 경우, 인덱스로 사용이 불가능
WITH
-
可使用子查询,像临时表或视图一样使用
-
可指定别名
-
被视为内联视图或临时表
-
以
WITH {table_name} AS {table_condition}
的形式使用
*
GROUP BY
-
根据条件进行分组的命令
-
若值的组合不同,则属于不同组
HAVING
-
基于分组后状态的条件语句
-
可使用 COUNT(计数)、SUM(求和)、AVG(平均值)、MAX(最大值)、MIN(最小值)、STDDEV(标准差)、VARIAN(方差)等
-
可使用 DISTINCT(去除重复)、ALL(全部)等条件
NULL 函数
NVL, ISNULL
-
若为 NULL 则替换为其他值的函数
-
数据类型不同时无法使用
*
NVL2
-
根据是否为NULL返回不同结果的函数
-
若非NULL则返回第1个参数,若为NULL则返回第2个参数
NULLIF
- 若两个参数相同则返回NULL,不同则返回第1个参数
*
COALESCE
- 返回第一个非NULL的值
GROUP 函数
分组对象列的值和聚合对象列的值将输出为NULL
可通过普通分组函数提取相同的结果
ROLLUP
-
显示部分和与总和。
-
函数的参数顺序会影响结果,并以分层结构返回聚合值。
CUBE
- 针对所有可分组的情况生成参数组合
GROUPING SETS
- 可按括号括起的集合进行聚合
*
GROUPING
- 当计算出小计、总计等时返回1,否则返回0的函数
JOIN
通常指表与表之间的连接,类似于集合
支持表与表之间、连接结果与表之间、以及连接结果之间的JOIN
当两个相关表至少存在一个共同属性时可应用
既有明确指定 JOIN 的 ANSI 标准查询,也存在未明确指定的非标准查询。
若列出了 JOIN,则每次处理两个,无法同时处理所有 JOIN
-
交集
*
INNER JOIN
-
非标准表示法,用 “ ” 缩写
-
连接两个表的交集
*
LEFT JOIN
-
非标准形式使用时,左侧标注 (+)
-
左侧表全部数据与右侧表的交集进行连接
*
RIGHT JOIN
-
非标准形式使用时,右侧标注 (+)
-
右侧表全部数据与左侧表的交集进行连接
*
OUTER JOIN
-
由于两侧均不可使用 (+) 符号,因此无法使用 OUTER JOIN,必须使用 ANSI 标准查询。
-
与 UNION 不同,即使仅存在一个共同属性也可应用。
-
-
并集
*
UNION (ALL)
-
当查询对象的列数相同且各列属性一致时可应用的连接方式
-
数据量为 Data1 + Data2。
-
UNION ALL 合并时不会去除重复数据
-
-
差集
当仅需确认排除交集后的单一集合时适用
*
MINUS(Oracle)
-
EXCEPT(SQL Server)
-
连接对象之间的一致程度
-
EQUI JOIN:使用相同的列连接两个关系
-
non-EQUI JOIN:使用不完全匹配的列连接两个关系
ex) A.key <, >, <=, >= B.key
-
-
CROSS JOIN
-
若不使用键进行连接,则会对两个表产生笛卡尔积
5개의 행 * 3개의 행 = 15개의 행으로 조회
*
自连接
-
在同一张表内,对具有关联关系的两个列进行连接
-
由于表名和列名完全一致,因此必须使用别名
优化器连接
- 在执行连接的过程中,为性能优化而选择的方法,需通过提示(Hint)指定
层级查询
对树形数据进行查询
-
层级结构的起点通过 START WITH 设定(ROOT NODE)
-
没有子节点的节点 = LEAF NODE
-
层级用 LEVEL 表示
CONNECT BY
-
确认层级结构的连接方向
-
子节点 > 父节点
-
父节点 > 子节点
-
*
##### CONNECT BY PRIOR a = b
* 当 a 列和 b 列在同一条记录中相同时,会形成层级关系
* 按 b -> a 的顺序重新排列
SIBLINGS BY
- 确定兄弟节点之间的排列顺序
窗口函数
用于轻松定义记录之间关系的函数,采用
SELECT WINDOW_FUNCTION {arguments} OVER {partition by column} {order_style} FROM {table};
的形式
*
WINDOW_FUNCTION
-
窗口函数
-
组内聚合函数:COUNT、SUM、MIN、MAX、AVG 等
-
组内排名函数
即使创建了排名函数,也不会自动排序,因此必须使用 ORDER BY 子句。
*
RANK
-
对相同排名赋予相同的排名
-
不将相同排名计为同一条记录
*
DENSE_RANK
-
对相同排名赋予相同的排名
-
将相同排名计为同一条记录
ROW_NUMBER
- 对相同排名赋予唯一的排名
-
-
组内比例相关函数
*
PERCENT_RANK
- 以“顺序”而非数值为对象,查询分区内各顺序对应的百分比
*
NTILE(n)
- 返回按分区将总记录数均分为 n 份后的数值
*
CUME_DIST
-
查询分区内当前行值及以下记录数的累积百分比
-
在累积分布中取值范围为 0 至 1
-
组内行序函数
*
FIRST_VALUE
- 返回分区内出现的第一个值
*
LAST_VALUE
- 返回分区内出现的最后一个值
*
LAG(column_name, record_difference)
- 获取前一行
*
LEAD(column_name, record_difference, value_if_null)
-
获取下一行。
-
默认值为 1
-
参数
- 参数(列名等函数操作的对象)
*
PARTITION BY
- 分割表中记录的依据
ORDER BY
- 指定在分割后的记录范围内或整个表中,按何种标准对记录进行排序
WINDOWING
-
确定函数运算对象的记录范围
*
RANGE
- 用于指定范围
*
BETWEEN a AND b
- 应用于从 a 到 b 的范围
*
UNBOUNDED PRECEDING
- 起始位置 = 第一行
*
UNBOUNDED FOLLOWING
- 起始位置 = 最后一行
*
CURRENT ROW
- 起始位置 = 当前行
表分区
将大型表拆分为多个数据文件进行存储
存储在物理上分离的数据文件中 => 性能提升且可独立管理
缩小查询范围的效果 => 性能提升
范围分区
- 基于值的范围进行分区存储的方法
列表分区
-
基于特定值进行分区
-
哈希分区
- 数据库管理系统自行使用哈希函数进行分区和管理的方式
优化器
即使是相同的SQL语句,根据执行方式的不同,性能也会有所差异(性能指标:耗时、资源使用量等)
因此,需要分析SQL语句并根据特定标准制定执行计划,此时便会使用优化器。
优化器可能会影响执行性能,但结果值不会改变。
SQL문 작성 => 파싱 (문법 검사, 구문 분석) => 옵티마이저 (비용 기반 / 규칙 기반) => 실행 계획 (PLAN_TABLE 저장) => SQL 실행
*
成本驱动
-
最新版本的Oracle默认使用成本驱动优化器
-
通过系统统计信息和对象统计信息计算该SQL语句执行的总成本,然后制定成本最低的执行计划
规则驱动
-
根据15项优先级规则制定执行计划
-
通常基于ROWID进行扫描的优先级最高
*
索引
-
按索引键排序 => 查找速度加快
-
主键(PK)会自动生成索引
-
可以在一张表上创建多个索引,一个索引可以由多个列组成
-
按降序创建和排序
-
不建议将频繁变化的属性设置为索引
-
除非是具有UNIQUE属性的索引,否则辅助索引允许输入重复数据。
-
与索引扫描相比,全表扫描可能更高效且在成本上更具优势
-
对于分区表,可以针对分区创建分区键索引,称为全局索引
-
索引增加必然导致数据量增加,因此可能会导致插入、删除和修改速度下降
-
所有数据类型均可创建索引
-
索引的种类包括顺序索引、位图索引、组合索引、簇索引和哈希索引。
*
#### SCAN 方式
*<br />
##### 唯一索引扫描 (Index Unique SCAN)
* 当索引键值不重复时,通过该键进行查找
*<br />
##### 唯一索引扫描 (Index Unique SCAN)
* 使用查询特定范围的 WHERE 子句来扫描该区域
* 根据范围的不同,可能只返回一个结果,甚至返回 0 个结果
*<br />
##### 索引全扫描
* 从索引的开头到结尾进行全范围扫描
优化器连接的类型
*
#### 嵌套循环连接
* 先查询外部(驱动)表以查找连接对象数据,再连接内部(从属)表
* 处理量由先行表的处理范围决定,因此需要寻找大小较小的先行表
* 行间处理和表间处理均按顺序进行
* 寻找最佳顺序至关重要
* 由于会发生随机访问(在先行表中引用第二个表时发生),为减少性能延迟,应尽量减少随机访问的发生
* 当先行表的处理范围较广或随机访问范围较广时,存在比排序合并连接(SORT MERGE JOIN)更不利的情况
* “必须使用索引”,使用唯一索引时更有利
* 适用于在线事务处理(OLTP)
* 与嵌套循环相同,根据满足先行表条件的记录数进行循环执行
*
#### 排序合并连接 (Sort Merge JOIN)
* 分别对两张表进行排序,完成后进行合并
* 由于涉及排序,当数据量较大时会变慢。
* 当待排序的数据量较大时,会使用临时磁盘,从而导致性能下降。
* 支持等值连接 (EQIU JOIN) 和非等值连接 (non-EQIU JOIN)
哈希连接
* 将两张表中较小的一张加载到哈希内存中,使用两张表的连接键生成哈希表
* 同时扫描两张表
* 先行表中必须先出现“较小数据”
* 能最大限度利用系统资源,但可能消耗过多资源,且存在负载过高等风险
* 在处理海量数据时表现出色
* 仅适用于等值连接(EQUI JOIN)
* 不使用索引
* 连接方式
```text
먼저 선행 테이블을 결정, 선행 테이블에서 주어진 조건에 해당하는 레코드를 선택
해당 행이 선택되면 JOIN Key를 기준으로 해시 함수를 사용
해시 테이블을 메인 메모리에 생성, 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
후행 테이블의 JOIN Key를 사용해서 해시함수를 적용, 해당 버킷을 검색
```
PL/SQL
一种通过扩展SQL实现多种过程化编程的语言
-
采用块结构,可按功能进行模块化
-
以 DECLARE 语句开头,通过声明变量和常量进行使用
- DECLARE、BEGIN ~ END 为必备,EXCEPTION 为可选
-
使用 DML、IF、LOOP 等多种过程化语言
-
内置于 Oracle 中,可与使用相同语言的程序兼容
-
提升应用程序的性能
-
可编写过程、用户定义函数和触发器对象
- 过程内部编写的程序代码由 PL/SQL 引擎处理,而一般的 SQL 语句则由 SQL 执行器处理
分布式数据库
一种由单个数据库管理系统(DBMS)通过网络控制物理上分离的数据库的 DB 形式
-
性能提升:由于分布式数据库可进行并行处理,因此速度较快
-
采用模块化设计,可在不影响其他模块的情况下更新系统
-
可通过添加分布式数据库来扩展容量
-
便于保护重要数据
-
可靠性高
-
管理与控制困难
-
安全管理和完整性控制困难
-
结构复杂
메모
count(*): 전체 행의 수를 카운팅, null 포함
count({column_name}) null 을 제외한 행의 수를 카운팅
null: 모르는 값을 상징, 값의 부재를 말함
(null is null) = TRUE
null과의 모든 비교는 null 반환
0 혹은 ' '과 동일한 값이 아님
서브쿼리: SELECT문 내의 SELECT문이 반복 사용된 쿼리, 단일행 및 다중행으로 구분
- 정렬을 수행하는 ORDER BY를 사용할 수 없다.
- 여러 행을 반환하는 서브 쿼리는 다중 행 연산자를, 단일 행을 반환하는 서브쿼리는 단일 행 연산자를 사용
- 메인 쿼리에서 서브 쿼리의 컬럼을 자유롭게 사용할 수 없음
- EXIST는 True 혹은 False를 반환한다
스칼라 서브쿼리: 한 행과 한 컬럼만 반환하는 서브쿼리
인라인뷰: 서브쿼리가 FROM 절 내에 쓰여진 것
view 테이블
- 사용상의 편의를 위해 사용
- 수행속도의 향상을 위해 사용
- SQL의 성능을 향상시키기 위해 사용
- 임시적인 작업을 위해 사용
- 보안관리를 위해 사용
실행 순서
SELECT ALIAS => FROM => WHERE => GROUP BY => HAVING => SELECT => ORDER BY
조회 행수 제한
몇 번째 행을 조회하는지 부여하는 조건문
ROWNUM {row_number}: Oracle
TOP {row_number}: SQL Server
LIMIT {row_number}: MySQL
ROWID
해당 데이터가 어떤 데이터 파일 상에서 어느 블록에 저장되었는지 알려준다.
데이터베이스에 저장되어 있는 데이터를 구분할 수 있는 유일한 값이다.
ROWID의 번호는 데이터 블록에 데이터가 저장된 순서이다.
테이블에 데이터를 입력하면 자동으로 생성된다.
댓글 작성
게시글에 대한 의견을 남겨 주세요.