
SQLD合格体験記と資料
SQLD合格体験記
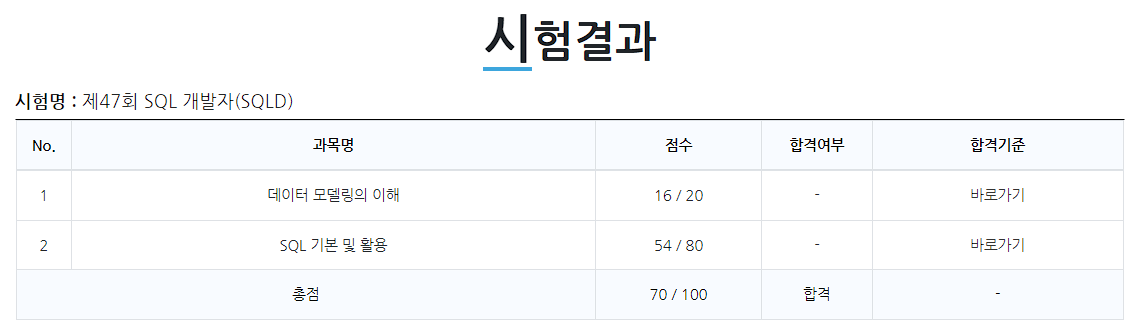 이미지를 불러올 수 없습니다.
이미지를 불러올 수 없습니다.
第47回SQL開発者資格試験に合格した。進路を完全に転換してから初めて取得した資格なので、とてもやりがいを感じている。
当初は1ヶ月ほど時間をかけようと思っていたが、他の用事に追われたり、理論的にばかりアプローチしすぎたりして……かなり時間を無駄にしてしまった気がして、残念な点もある。 勉強しながら確認した点をここに記しておく。
最後のパートには個人的に整理した概念が記載されているが、その後で実戦的な部分や、自分が覚えやすいように編集した点が所々に残っており、整合しない部分などが存在するかもしれない!それでも、もし誰かが勉強する際に役立つかもしれないので、全体の内容を残しておき、後で思い出したら編集する予定だ。
所要時間および勉強方法
実質的に費やした時間は約2週間、問題演習には約1週間を費やした。
最初は[Data on Air](https://dataonair.or.kr/
)が提供する概念解説を通じて、王道に近い方向で勉強を進めたかったが、SQLD自体が概念的な部分よりも実戦的なSQL構文の形で出題される問題の方がはるかに多いことを知り、序盤で断念することになった。しかし、依然として内容自体は良いと思うので、時間があれば一度確認することをお勧めする!
次に、YouTubeにある様々な形式の講義を通じて、大まかな概要を把握した。SQLDに限っては、かなり多くの整理された講義が存在するため、良さそうなものを選んで視聴するだけで十分だろう。
最後に問題演習だが、問題に関しては関連するカフェやブログに過去問を復元した資料が存在する。いわゆる「ノランイ」と呼ばれる本も良いが、過去問の解説も疎かにしないことが重要だ!ノランイの場合は第2章まで1回通読し、誤答ノートを整理するにとどめ、残りの時間はすべて過去問の演習に費やした。
個人的に推奨する過去問復元サイトは、[このブログ](https://yunamom.tistory.com/category/자격증/SQLD 기출문제
)をお勧めしたい。解答を入力するだけで、即座にその問題の正誤を確認できるからだ。
概念の整理
参考事項:第1章は第2章に比べて問題の比重が低いため後回しにされ、それに伴い必要な内容のみを記載しているため、内容が不十分である可能性がある
第1章
エンティティの分類
-
基本/キーエンティティ
-
中心エンティティ
-
行為エンティティ
データモデリング
-
情報システム構築のための、データ視点による業務分析手法
-
現実世界のデータを、定められた表記法によって表現
-
データベースを構築するための分析/設計のプロセス
データモデリングを行う際の留意点
-
重複
-
柔軟性の欠如
-
不整合
データモデリングの種類
-
概念的:抽象化レベルが高く、業務中心に包括的に進める
-
論理的:キー、属性、関係などを正確に表現し、再利用性が高くなるよう設計する
-
物理的:実際のデータベースに移植できるようにし、物理的な特性を考慮する
データベーススキーマの構造
-
外部
-
概念
-
内部
ERDの作成手順
- エンティティを描く。
- エンティティを適切に配置する。
- エンティティ間の関係を設定する。
- 関係名を記述する。
- 関係参加度を記述する。
- 関係の必須・非必須を記述する。
エンティティの特徴
-
当該業務において必要であり、管理すべき情報
-
一意の識別子でなければならない。
-
2つ以上のインスタンスを持つ。
-
実際に使用されなければならない。
-
属性を持たなければならない。
-
少なくとも1つ以上の関係を形成しなければならない。
1개 엔터티: 2개 이상의 인스턴스 집합 + 2개 이상의 속성
1개 속성: 1개 이상의 속성값
属性の特性による分類
-
基本属性
-
設計属性
-
派生属性
ドメイン
-
各属性が持つことができる値の範囲
-
エンティティ内の属性に対するデータ型、サイズ、制約の指定
属性の命名
-
当該業務で使用される名称でなければならない。
-
記述的な属性名は使用しない。
-
略語の使用は控える。
-
データモデル全体で一意性を確保しなければならない。
ERDでは実体関係と行為関係を区別しない。 しかし、クラス図では区別し、関連関係、依存関係を記述しなければならない。
関係の表記法
-
関係名:関係の名前
-
関係次数:1:1、1:M、M:N
-
関係選択仕様:必須、選択
関係の読み方
-
基準エンティティを「1つ(One)」または「各(Each)」と読む。
-
対象エンティティの関係参加度を読み取る。
-
関係の選択仕様と関係名を読み取る。
識別子の種類
-
代表性:主識別子 vs 副識別子
-
自己生成の有無:内部 vs 外部
-
単一属性識別:単一 vs 複合
-
意味の有無:本質的 vs 人工的
主識別子の特徴
-
一意性
-
希少性
-
不変性
-
存在性
パフォーマンスデータモデリング
データベースのパフォーマンス向上を目的として、パフォーマンス関連事項をデータモデリングに反映
第1正規化の対象
-
重複属性の分離
-
行単位の重複
-
カラム単位の重複
半正規化
正規化されたエンティティ、属性、関係の重複、統合、分離を通じて システムのパフォーマンスを向上させ、開発および運用の簡素化を図る 整合性が損なわれる可能性があるにもかかわらず、パフォーマンスの低下が予想される場合に実施する。
手順
-
半正規化の対象の調査
-
範囲処理の頻度
-
大量の範囲処理
-
統計的処理
-
テーブル結合(JOIN)の数
-
-
他の方法で対応可能な場合は、その方法への誘導を検討
-
結合(JOIN)が多い場合は、ビュー(view)やテーブルを使用
-
大量のデータ処理時にはクラスタリング
-
大量のデータを保有する場合は、パーティショニングによるデータ分割
-
インデックスのメンテナンス
-
アプリケーションのロジック変更
-
スーパー/サブタイプ データモデル変換技術
個別に発生するトランザクション → 個別テーブル スーパー+サブタイプ → スーパー+サブテーブル 全体 → 単一のテーブル
PKの順序を決定する基準
-
インデックスを効率的に利用できるよう指定
-
先頭にある属性の値が比較対象となること
-
可能な限り「=」、「BETWEEN」、「<>」
分散データベースの長所および短所
長所
-
局所性、システムの容量を段階的に拡張可能
-
信頼性と可用性/有用性と柔軟性
-
高速な応答速度、通信コストの削減、地域ユーザーのニーズへの対応力向上
-
データの可用性と信頼性の向上、システム規模の調整
短所
-
開発コストおよびエラー発生の可能性の増加、処理コストの増加、データの完全性を脅かす
-
設計プロセスの困難さ、管理の複雑さとコスト、不安定な応答速度、制御の難しさ
第2章
SQL文の種類
DCL
Data Control Language、権限を管理するコマンド
GRANT
-
権限を付与する役割
-
``GRANT {permission} ON {table} TO {user};`
の形式で使用
```text
WITH GRANT, WITH ADMIN의 비교
GRANT: 특정 사용자에게 권한 부여가 가능한 권한을 부여, 부여한 부모의 권한이 회수될 때 자식의 권한도 회수
ADMIN: 테이블에 대한 모든 권한을 부여, 부여한 부모의 권한 회수와 관계 없는 권한
```
`
REVOKE
-
権限を取り消す役割
-
``REVOKE {permission} ON {table} FROM {user};`
` の形式で使用
*
権限の種類
ALL -- 모든 권한 부여
SELECT INSERT UPDATE DELETE /* */
REFERENCES ALTER INDEX /* */
/* ROLE: 다양한 권한을 하나의 그룹으로 묶어서 관리 */
CREATE ROLE {role_name}; -- 권한 그룹 생성
GRANT {permission_type} TO {role_name}; -- 해당 그룹에 권한 등록
GRANT {role_name} TO {user_1}, {user_2}...; -- 다른 유저들에게 권한 그룹 부여
DDL
Data Definition Language、データを定義するコマンド
SQL Server では Auto Commit をサポート
CREATE
-
テーブル構造の作成
-
「
CREATE TABLE {table_name} {table_elements};
」の形式で使用
```sql
CREATE TABLE EXAMPLE (
/*
컬럼명은 영어, 한글, 숫자 전부 가능
첫 글자를 문자로 지정해야 하며, 컬럼의 데이터 타입은 반드시 설정해야 한다.
*/
NAME varchar2(max_length) -- 최대 길이를 가진 가변길이 문자열
ID번호 char(length) -- 고정된 길이 문자열
나이_2 number(max_length) -- 숫자형 데이터 타입
생일 date -- 날짜형 데이터 타입
);
```
*
##### CONSTRAINT (制約)
* default: デフォルト値の指定
* not null: NULL値の入力不可
* primary key: 主キーの指定 (not null, unique, 複数可)
* foreign key: 外部キーの指定 (複数可)
ALTER
-
テーブルおよびカラムに対して、名前や属性の変更、追加、削除などの構造修正を行う
-
「
ALTER TABLE {table_name} {detail_order} {detail_property(if need)} TO {change_target};
」の形式で使用
*
#### 詳細なコマンド
* RENAME: テーブル、カラムの名前を変更
* MODIFY: カラムの属性を変更
* ADD: カラムを追加
* DROP: カラムを削除
* ADD CONSTRAINT / DROP CONSTRAINT: 制約を追加、削除
*
RENAME
-
ALTERを使用せずに、テーブルやカラムの名前を変更できる
-
複数のテーブル名を同時に変更可能
DROP
- ALTERを使用せずに、テーブルやカラムを削除できる
*
#### TABLE {table_name} CASCADE CONSTRAINT
* Oracleにのみ存在するオプションで、SQL Serverには存在しない
* 外部キー制約において、参照テーブルを先に削除し、その後、対象テーブルを削除する。
* 対象テーブルのデータおよび外部キー参照制約もすべて削除する
TRUNCATE
-
テーブルの初期化 (削除ではない!)
-
内部データのみが削除され、テーブルの存在およびカラムは残る。
*
#### DROP vs TRUNCATE vs DELETE
* DROP: テーブルを丸ごと削除した後、メモリを解放
* TRUNCATE: テーブル、カラムの存在は残り、残りのデータに対するメモリを解放
* DELETE: レコードを削除。データに対するログが残るため、反映されるまではロールバックが可能。メモリは解放されない
DML
Data Manipulation Language(データ操作言語)。レコードを操作するコマンド
INSERT
-
データをレコードに入力
-
``INSERT INTO {table_name} {column_name} VALUES {change_column_name};`
` の形式で使用する
- カラム名を指定しなくても入力可能だが、指定しない場合はすべての値を入力する必要がある。
UPDATE
-
既存のデータを修正
-
``UPDATE {table_name} SET {column_name} = {column_value} WHERE {condition};`
` の形式で使用する
DELETE
-
既存のデータを削除
-
``DELETE FROM {table_name} WHERE {condition};`
` の形式で使用する
FROMは省略可能
*
SELECT
-
特定のデータを照会
-
``SELECT {select_target} FROM {select_origin} WHERE {condition};`
` の形式で使用する
- ``GROUP BY {calc_type} HAVING {condition} / ORDER BY {sort_condition}`
` の形式で条件を指定することもある
*
#### DISTINCT
重複値を除いて照会する条件 (a, b, NULL, a, b, NULL) => (a, b, NULL)
COUNT
(\*): NULL値を含めて全行数をカウント
({column\_name}): NULLを除いて特定のカラムの行数をカウント
TCL
Transaction Control Language、トランザクション制御コマンド
Transaction: DBの状態を変化させる操作
* transaction의 특징
고립성: 실행되는 동안 다른 transaction에 영향을 받아 잘못된 결과를 만들면 안됨
일관성: 실행 전 데이터베이스에 잘못된 점이 없다면 transaction 수행 후에도 내용에 오류가 있으면 안됨
지속성: transaction이 갱신한 데이터베이스 내용은 영구적으로 저장
원자성: transaction에서 정의한 연산은 모두 성공적으로 실행되거나 전혀 실행되지 않음 (All or Nothing)
COMMIT
- データへの変更をDBに反映
SAVEPOINT
-
コード分割の分岐点となるようsavepointを指定
-
``SAVEPOINT {savepoint_name};`
` の形式で使用
ROLLBACK
-
以前の状態に戻すコマンド
-
SAVEPOINTまたは直前のCOMMITまでロールバックが可能
*ROLLBACK TO {rollback_point};
の形式で使用
- セーブポイントがない場合は、最新のCOMMIT時点に復元
TCLの効果
-
データ整合性の保証
-
永続的なデータ変更前に、変更内容を確認
-
論理的に関連する処理をグループ化して処理可能
関数
文字列関数
SELECT、WHEREなどの条件を指定する際によく使用される
LOWER
- 英字文字列を小文字に変換
UPPER
- 英字文字列を大文字に変換
CONCAT
-
2つの文字列を結合
-
Oracleの'||'、SQL Serverの'+'と同様の役割
SUBSTR
- 文字列のM番目の位置からN文字を残して削除
LENGTH, LEN
- 空白を含む文字列の長さ
TRIM, LTRIM, RTRIM
- 両端の指定された文字をすべて削除。指定された文字がない場合は空白を削除
数値型関数
ROUND
- 四捨五入
TRUNC
- 切り捨て
CEIL
- それ以上の最小の整数
*
FLOOR
- 以下となる最大の整数
MOD
- 剰余演算
SIGN
- 正の数は1、0は0、負の数は-1を返す
ABS
- 絶対値
日付型関数
SYSDATE
- クエリを実行している現在の日付および時刻を出力
EXTRACT
- ``EXTRACT ({information} FROM {data})`
` の形式で使用
- 日付型データから必要な値を抽出する方法
型変換
これらの関数を使用してデータ型を変更できる
*
TO_NUMBER
文字列 > 数値
TO_CHAR
数値、日付 > 文字列(フォーマットによって生成結果が異なる)
TO_DATE
文字列 > 日付(フォーマットによって生成結果が異なる)
基本構造
*
DECODE
-
IF文
-
条件がシンプルに整理できる場合
*
CASE WHEN
-
長くなったIF文
-
条件の整理に多くの行数が必要な場合
ORDER BY
-
取得したテーブルのソート
-
基準を複数使用可能
-
WHERE
-
IN, NOT IN: リスト内の値のいずれか一つでも一致、または不一致であれば条件を満たす
-
IS NULL, IS NOT NULL: NULLかどうかを判断して T / F を返す
-
BETWEEN a AND b: a と b の間に値が存在するかどうかを確認して T / F を返す(a と b を含む)
-
比較演算子:=、>、<、>=、<= など
-
A LIKE B:a に対して b と類似した文字列を検索する
-
%:1文字以上が存在することを意味する
-
_:1文字
명시적 형변환 vs 암시적 형변환
명시적 형변환: 함수를 활용하여 데이터 타입을 변경
암시적 형변환: 데이터베이스가 알아서 바꿔주는 것
>> 숫자 타입의 PK는 암묵적으로 인덱스가 되는데 데이터의 조회 등으로 암시적 형변환이 발생한 경우, 인덱스로 사용이 불가능
*
WITH
-
サブクエリを使用して、一時テーブルやビューのように使用可能
-
別名を指定可能
-
インラインビューまたは一時テーブルとして扱われる
-
``WITH {table_name} AS {table_condition}`
` の形式で使用
GROUP BY
-
条件に基づいてグループ化を行う命令
-
値の組み合わせが異なれば別のグループ
HAVING
-
グループ化後の状態に基づく条件文
-
COUNT(カウント)、SUM(合計)、AVG(平均)、MAX(最大)、MIN(最小)、STDDEV(標準偏差)、VARIAN(分散)など
-
DISTINCT(重複除去)、ALL(すべて)などの条件を使用可能
NULL関数
NVL、ISNULL
-
NULLの場合、別の値に変更する関数
-
データ型が異なる場合は使用できない
NVL2
-
NULLかどうかによって異なる結果を返す関数
-
NULLでない場合は第1引数、NULLの場合は第2引数を返す
NULLIF
- 2つの引数が同じ場合はNULLを返し、異なる場合は第1引数を返す
*
COALESCE
- NULLではない最初の値を返す
GROUP関数
グループ化対象の列値、集計対象の列値はNULLとして出力される
一般的なグループ関数でも同様の結果を抽出できる
ROLLUP
-
部分合計と全体合計を表示する。
-
関数の引数が与えられた順序によって結果値が異なり、階層構造で集計値を返す。
CUBE
- グループ化可能なすべてのケースについて、引数の集合を生成する
GROUPING SETS
- 括弧で囲んだ集合ごとの集計が可能
*
GROUPING
- 小計、合計などが計算された場合は1を返し、そうでない場合は0を返す関数
JOIN
一般的にテーブル間の結合であり、集合に類似している
テーブルとテーブル、結合結果とテーブル、結合結果同士のJOINが可能
関連する2つのテーブルに少なくとも1つの共通属性が存在する場合に適用可能
JOINを明示するANSI標準形式のクエリと、そうでない非標準形式のクエリが存在する。
JOINが列挙されている場合、一度に2つずつ処理され、すべてを同時に処理することはできない
-
共通部分
*
INNER JOIN
-
非標準形式の表記では、に省略
-
両方のテーブルの共通部分(交差)を結合
*
LEFT JOIN
-
非標準表記を使用する場合、左側に (+) を表記
-
左側のテーブルの全レコードと、右側のテーブルの共通部分のみを結合
RIGHT JOIN
-
非標準表記を使用する場合、右側に (+) を表記
-
右側のテーブルの全レコードと、左側のテーブルの共通レコードのみを結合
*
OUTER JOIN
-
両側に「+」を使用できないためOUTER JOINは使用できず、ANSI標準形式のクエリを使用する必要がある。
-
UNIONとは異なり、共通属性が1つだけ存在しても適用可能。
-
-
和集合
*
UNION (ALL)
-
照会対象の列数が同じで、各列の属性が同一の場合に適用できる結合方式
-
データ量は Data1 + Data2 となる。
-
UNION ALL は重複データを削除せずに結合する
-
-
差集合
交集合を除外し、一つの集合のみを確認したい場合に適用可能
*
MINUS(Oracle)
-
EXCEPT(SQL Server)
-
結合対象間の一致度
-
EQUI JOIN: 同一の列を使用して2つのリレーションを結合
-
non-EQUI JOIN: 正確に一致しない列を使用して2つのリレーションを結合
ex) A.key <, >, <=, >= B.key
-
-
CROSS JOIN
-
キーなしでJOINすると、2つのテーブルに対してデカルト積が発生する
5개의 행 * 3개의 행 = 15개의 행으로 조회
SELF JOIN
-
1つのテーブル内で関連性を持つ2つのカラム間のJOIN
-
テーブル名およびカラム名がすべて一致するため、ALIASの使用が必須
*
オプティマイザ・ジョイン
- JOINを実行する過程で、パフォーマンス最適化のための方式を選択し、Hintとして指定する
階層型クエリ
ツリー形式のデータに対してクエリを実行すること
-
階層構造の開始点はSTART WITHで設定(ROOT NODE)
-
子ノードを持たないノード = LEAF NODE
-
階層をLEVELで表記
*
CONNECT BY
-
階層構造の接続方向性を確認
-
子 > 親
-
親 > 子
-
*
##### CONNECT BY PRIOR a = b
* a 列と b 列が同一レコード間で階層化が発生
* b -> a の順に再配置
SIBLINGS BY
- 兄弟ノード間の配置順序を決定
WINDOW関数
レコード間の関係を簡単に定義するための関数。
SELECT WINDOW_FUNCTION {arguments} OVER {partition by column} {order_style} FROM {table};
の形式で使用
WINDOW_FUNCTION
-
ウィンドウ関数
-
グループ内の集計関数:COUNT、SUM、MIN、MAX、AVGなど
-
グループ内の順位関数
順位関数を作成しても自動的にソートは行われないため、ORDER BY句を活用する必要がある。
*
RANK
-
同一の順位に対しては同一の順位を付与
-
同一の順位を1件としてカウントしない
*
DENSE_RANK
-
同一順位には同一の順位を付与
-
同一順位を1件としてカウント
*
ROW_NUMBER
- 同一順位には一意の順位を付与
-
-
グループ内の比率関連関数
*
PERCENT_RANK
- 値ではなく「順序」を対象とし、パーティション内での順序ごとの百分率を照会する
*
NTILE(n)
- パーティションごとに総件数をn等分した値を返す
*
CUME_DIST
-
パーティション全体において、現在の行の値以下のレコード数に対する累積割合を取得する
-
累積分布上で0~1の値をとる
-
グループ内の行順序関数
*
FIRST_VALUE
- パーティション内で最初に現れる値を返す
*
LAST_VALUE
- パーティション内で最後に現れる値を返す
*
LAG(column_name, record_difference)
- 前の行を取得する
*
LEAD(column_name, record_difference, value_if_null)
-
次の行を取得する。
-
DEFAULT = 1
-
ARGUMENTS
- 引数(列名など、関数の処理が行われる対象)
PARTITION BY
- テーブルのレコードを分割する基準
ORDER BY
- 分割されたレコード内、またはテーブル全体において、レコードをどのような基準で並べ替えるかを指定
WINDOWING
-
関数の演算対象となるレコードの範囲を指定
*
RANGE
- 範囲指定時に使用
*
BETWEEN a AND b
- aからbまでを適用
*
UNBOUNDED PRECEDING
- 開始位置 = 最初の行
*
UNBOUNDED FOLLOWING
- 開始位置 = 最後の行
*
CURRENT ROW
- 開始位置 = 現在の行
テーブルパーティション
大容量のテーブルを複数のデータファイルに分割して保存すること
物理的に分離されたデータファイルに保存 => パフォーマンスの向上および独立した管理が可能
検索範囲を狭める効果 => パフォーマンスの向上
RANGE PARTITION
- 値の範囲を基準にパーティションを分割して保存する方法
LIST PARTITION
-
特定の値を基準に分割
-
ハッシュパーティション
- データベース管理システムが独自にハッシュ関数を使用して分割・管理する方式
オプティマイザ
同じSQL文であっても、その実行方法によってパフォーマンスが異なる(パフォーマンスの指標:所要時間、リソース使用量など)
したがって、SQL文を分析し、一定の基準に基づいて実行計画を立てる必要があり、この際にオプティマイザを使用する。
オプティマイザは実行パフォーマンスに影響を与える可能性はあるが、結果値は変わらない。
SQL문 작성 => 파싱 (문법 검사, 구문 분석) => 옵티마이저 (비용 기반 / 규칙 기반) => 실행 계획 (PLAN_TABLE 저장) => SQL 실행
コストベース
-
最新のOracleでは、コストベースのオプティマイザがデフォルトで使用される
-
システム統計とオブジェクト統計を通じて、当該SQL文の実行にかかる総コストを計算した後、最小コストの実行計画を策定
*
コストベース
-
最新のOracleでは、コストベースのオプティマイザがデフォルトで使用される
-
システム統計とオブジェクト統計を通じて、当該SQL文の実行にかかる総コストを計算し、最小コストの実行計画を策定する
ルールベース
-
15種類の優先順位に基づいて実行計画を策定する
-
一般的に、ROWIDに基づいてスキャンすることが最も優先順位が高い
インデックス
-
インデックスキーに基づいてソートされる => 検索が高速化される
-
PKは自動的にインデックス化される
-
1つのテーブルに複数のインデックスを作成でき、1つのインデックスが複数のカラムで構成されることもある
-
降順で作成およびソートされる
-
頻繁に変化する属性をインデックスに設定するのは好ましくない
-
セカンダリインデックスには、UNIQUE属性のインデックスでない限り、重複データの入力が可能である。
-
インデックススキャンよりもフルスキャンの方が効率的であり、コスト面でも有利な場合がある
-
パーティションテーブルでは、パーティションに対してパーティションキーインデックスを作成可能であり、これをグローバルインデックスと呼ぶ
-
インデックスが増えると当然データ量も増加するため、挿入、削除、更新の速度低下を招く可能性がある
-
すべてのデータ型でインデックスの作成が可能
-
インデックスの種類として、シーケンシャルインデックス、ビットマップ、結合インデックス、クラスター、ハッシュインデックスが存在する。
*
#### SCAN方式
*<br />
##### Index Unique SCAN
* インデックスキーの値が重複しない場合、そのキーを通じて検索を行う
*<br />
##### Index Unique SCAN
* 特定の範囲を照会するWHERE句を使用して、該当領域をスキャン
* 範囲によっては、1件または0件の結果が出力されることもある
*<br />
##### Index Full SCAN
* インデックスの先頭から末尾まで全てをスキャン
オプティマイザ結合の種類
*
#### Nested Loop JOIN
* 外部(先行、Driving)テーブルを先に検索して結合対象データを見つけ、内部(後続)テーブルと結合
* 先行テーブルの処理範囲によって処理量が決定されるため、先行テーブルのサイズが小さいものを見つける必要がある
* 行間処理、テーブル間処理のいずれも順次発生
* 最適な順序を見つけることが重要
* ランダムアクセスが発生するため(先行テーブルから2番目のテーブルを参照する際に発生)、パフォーマンスの遅延を低減するために、ランダムアクセスの発生を少なくする必要がある
* 先行テーブルの処理範囲が広かったり、ランダムアクセスの範囲が広かったりする場合は、SORT MERGE JOINよりも不利になるケースがある
* 「インデックス必須」、一意インデックスの場合は有利
* オンライントランザクション処理(OLTP)に有用
* ネストされたループと同じ形式で、先行テーブルの条件を満たすケースの数だけ反復的に実行
*
#### ソートマージ結合(Sort Merge JOIN)
* 2つのテーブルをそれぞれソートし、完了後にマージ
* ソートが発生するため、データ量が多い場合は処理が遅くなる。
* ソート対象のデータ量が多い場合、一時ディスクを使用するため、パフォーマンスが低下する。
* EQIU JOIN、non-EQIU JOINの両方が可能
HASH JOIN
* 2つのテーブルのうち小さい方のテーブルをHASHメモリにロードし、2つのテーブルのJOINキーを使用してハッシュテーブルを作成
* 2つのテーブルを同時にスキャン
* 先行テーブルには「データ量の少ない方」が先に来る必要がある
* システムリソースを最大限に活用可能だが、リソースを過剰に消費する可能性があり、負荷などの懸念がある
* 大容量処理において高速な処理速度を示す
* EQUI JOINでのみ可能
* インデックスを使用しない
* JOIN方式
```text
먼저 선행 테이블을 결정, 선행 테이블에서 주어진 조건에 해당하는 레코드를 선택
해당 행이 선택되면 JOIN Key를 기준으로 해시 함수를 사용
해시 테이블을 메인 메모리에 생성, 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
후행 테이블의 JOIN Key를 사용해서 해시함수를 적용, 해당 버킷을 검색
```
PL/SQL
SQLを拡張し、多様な手続き型プログラミングを可能にした言語
-
ブロック構造になっているため、機能別にモジュール化が可能
-
DECLARE文で始まり、変数および定数を宣言して使用可能
- DECLARE、BEGIN ~ ENDは必須、EXCEPTIONは任意
-
DML、IF、LOOPなど、様々な手続き型言語を使用
-
Oracleに組み込まれており、同じ言語を使用するプログラムとの互換性がある
-
アプリケーションのパフォーマンスを向上させる
-
Procedure、User Defined Function、Triggerオブジェクトを作成できる。
- プロシージャ内部に記述された手続き型コードはPL/SQLエンジンが処理し、一般的なSQL文はSQL実行エンジンが処理する。
分散データベース
単一のデータベースシステム(DBMS)がネットワークを介して物理的に分離されたデータベース群を制御する形態のDB
-
性能向上:分散データベースは並列処理を行うため、処理速度が速い
-
モジュール化されているため、他のモジュールに影響を与えることなくシステムの更新が可能
-
分散データベースの追加による容量の拡張が可能
-
重要データの保護が容易
-
信頼性が高い
-
管理および制御の難しさ
-
セキュリティ管理、整合性制御の難しさ
-
複雑な構造
메모
count(*): 전체 행의 수를 카운팅, null 포함
count({column_name}) null 을 제외한 행의 수를 카운팅
null: 모르는 값을 상징, 값의 부재를 말함
(null is null) = TRUE
null과의 모든 비교는 null 반환
0 혹은 ' '과 동일한 값이 아님
서브쿼리: SELECT문 내의 SELECT문이 반복 사용된 쿼리, 단일행 및 다중행으로 구분
- 정렬을 수행하는 ORDER BY를 사용할 수 없다.
- 여러 행을 반환하는 서브 쿼리는 다중 행 연산자를, 단일 행을 반환하는 서브쿼리는 단일 행 연산자를 사용
- 메인 쿼리에서 서브 쿼리의 컬럼을 자유롭게 사용할 수 없음
- EXIST는 True 혹은 False를 반환한다
스칼라 서브쿼리: 한 행과 한 컬럼만 반환하는 서브쿼리
인라인뷰: 서브쿼리가 FROM 절 내에 쓰여진 것
view 테이블
- 사용상의 편의를 위해 사용
- 수행속도의 향상을 위해 사용
- SQL의 성능을 향상시키기 위해 사용
- 임시적인 작업을 위해 사용
- 보안관리를 위해 사용
실행 순서
SELECT ALIAS => FROM => WHERE => GROUP BY => HAVING => SELECT => ORDER BY
조회 행수 제한
몇 번째 행을 조회하는지 부여하는 조건문
ROWNUM {row_number}: Oracle
TOP {row_number}: SQL Server
LIMIT {row_number}: MySQL
ROWID
해당 데이터가 어떤 데이터 파일 상에서 어느 블록에 저장되었는지 알려준다.
데이터베이스에 저장되어 있는 데이터를 구분할 수 있는 유일한 값이다.
ROWID의 번호는 데이터 블록에 데이터가 저장된 순서이다.
테이블에 데이터를 입력하면 자동으로 생성된다.
댓글 작성
게시글에 대한 의견을 남겨 주세요.